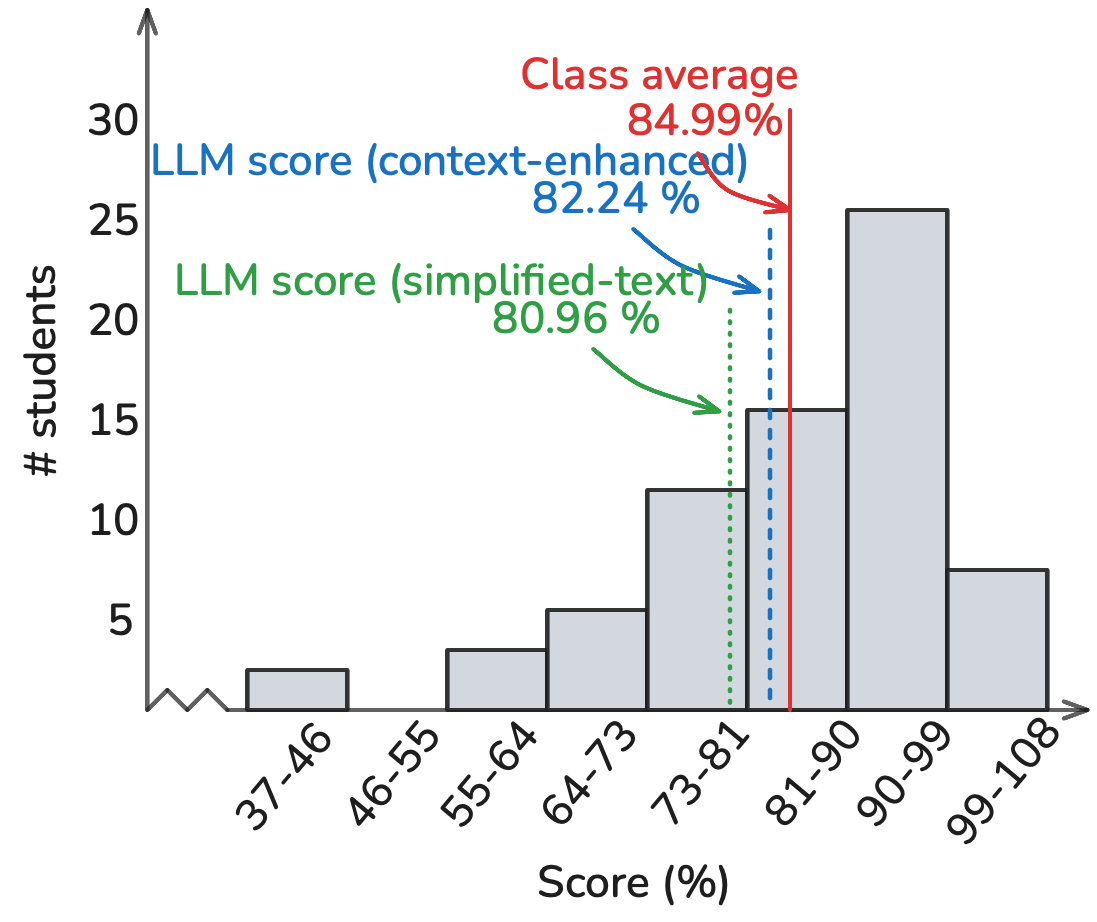
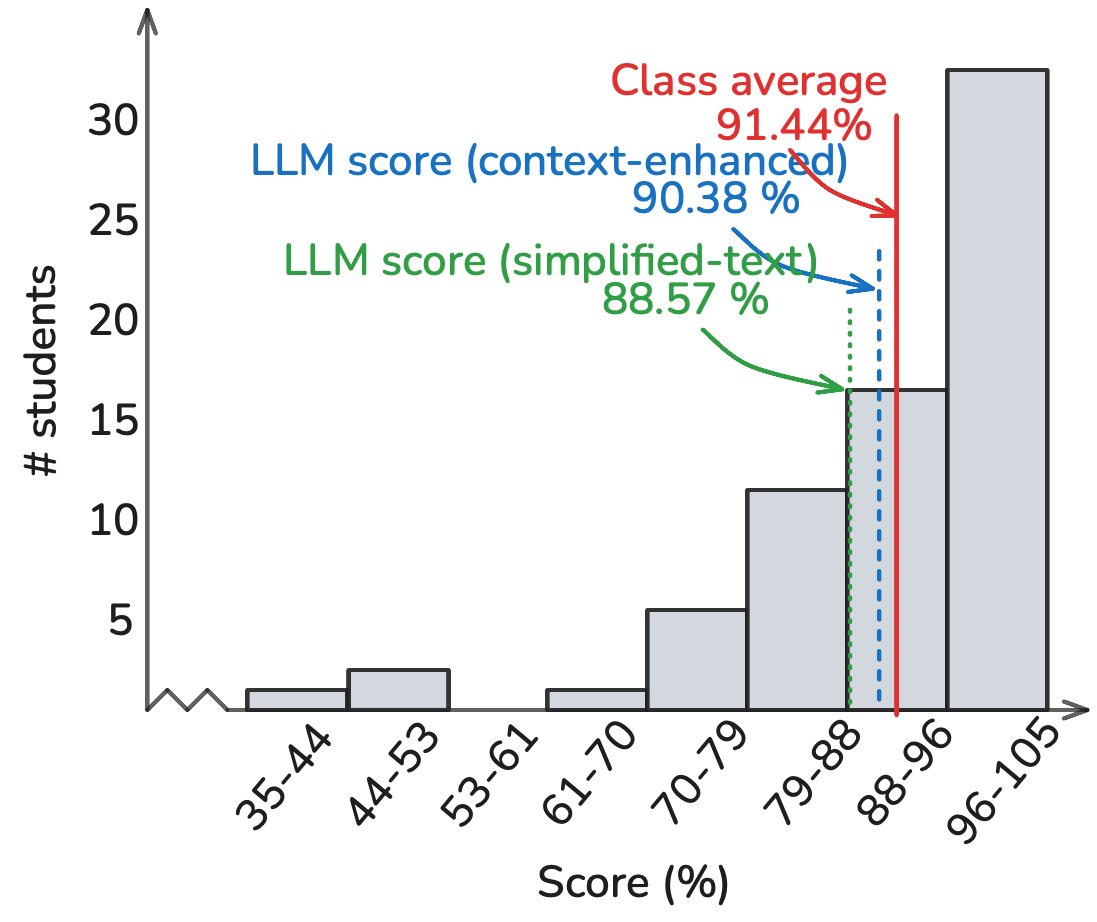
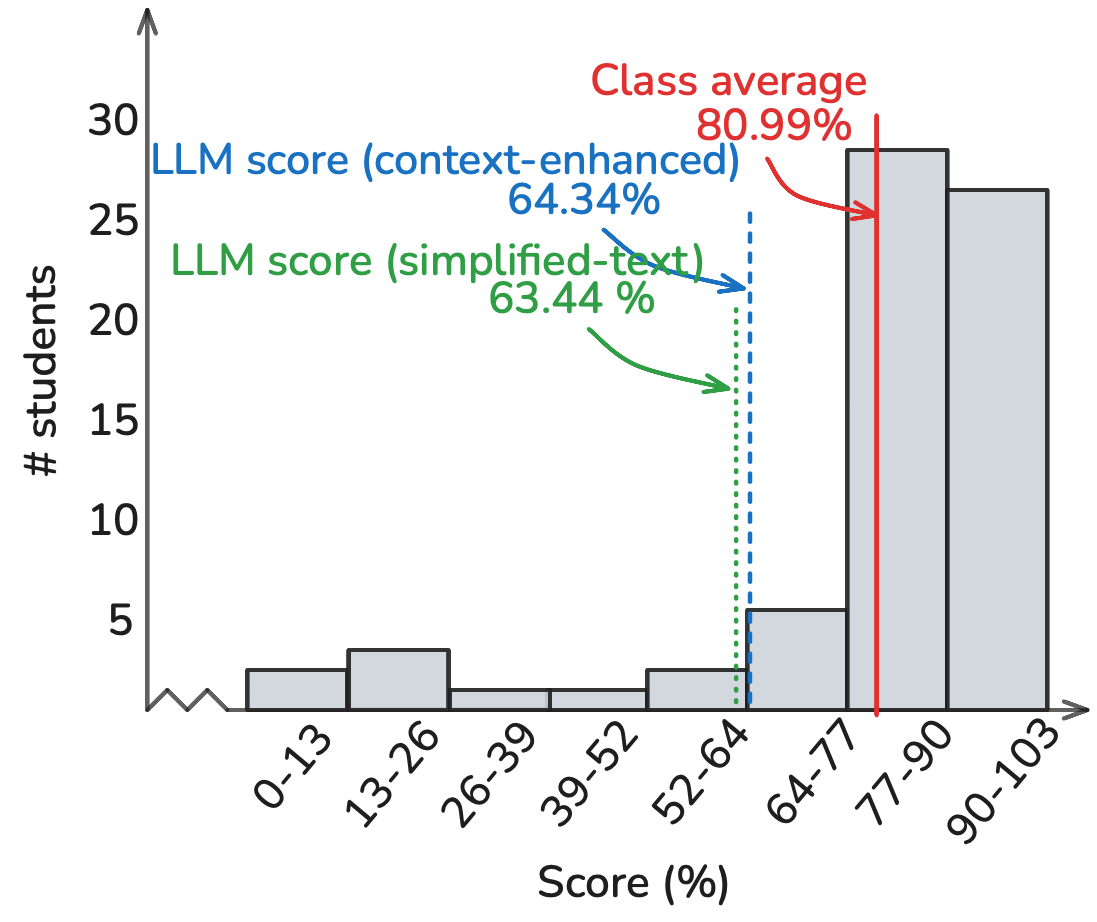
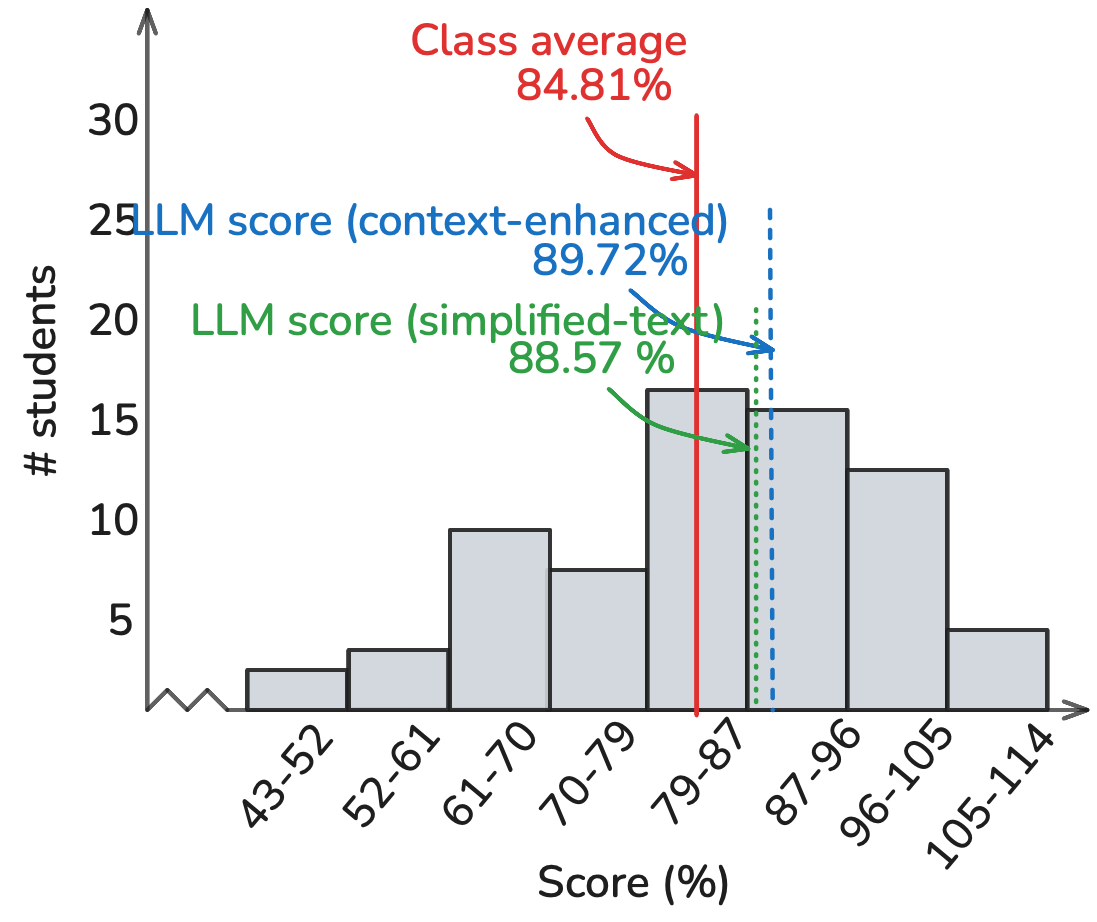
Homework Performance:
Homework performance reveals subtle patterns across question types. The LLM achieved 90.38% against a class average of 91.44%, with performance varying by question type. MCQs showed the highest success, followed by code-based questions, MCMCQ, and numerical problems. This hierarchy persisted across all prompting methodologies, though with varying gaps. The multi-shot approach proved particularly effective for MCQs. Analysis of the 92 homework questions reveals that performance degradation correlated strongly with question complexity: single-concept questions saw higher success rates compared to integration-heavy problems.
Examination Performance:
Examination analysis provides critical insights into LLM capabilities under different assessment conditions. The model achieved 89.72% overall compared to the class average of 84.81%, but this aggregate masks important variations. Auto-graded components of the final (97.4%) significantly outperformed written sections (86.5%), with midterm performance (89.8%) showing intermediate results. This pattern held consistent across prompting methodologies. The performance gap between written and auto-graded components suggests fundamental differences in the model's ability to handle structured versus open-ended problems.
Project Performance:
Project evaluation exposed systematic limitations in LLM capabilities, with the most significant performance gap observed (64.34% versus class average 80.99%). The distinction between code implementation and report writing reveals specific challenges. Code submissions showed consistent patterns of failure in system integration, error handling, and optimization, while maintaining basic functional correctness. Report analysis indicates stronger performance in methodology description and result presentation but weaker performance in critical analysis and design justification. Neither image-based nor multi-shot approaches provided significant improvements in project performance, suggesting fundamental limitations rather than methodology-dependent constraints.